
Az alábbi cikk az attribúciós/hozzárendelési modellezés összetett világát hivatott egy kicsit hétköznapibb, gyakorlatiasabb perspektívába helyezni. A cikk végén található egy TL;DR verzió, de ajánlom a cikk végigolvasását mindenkinek, aki az online értékesítés világában tevékenykedik.

Bevezetés
Az attribúciós avagy hozzárendelési modellezés az egyik legösszetettebb analitikai téma, ezért gyakran nem kapja meg a neki kijáró figyelmet. Ez végzetes hiba.
Pedig a legalapvetőbb üzletvezetési, kiértékelési kérdésekkel foglalkozik.
Hogyan teljesítenek a kampányaim?
Hogyan teljesíthetnének még jobban?
Túl- vagy esetleg alulértékelt XY csatorna?
Mi alapján optimalizáljak?
Ha csökkentem a Display kampányaim költését, milyen hatása lesz a bevételeimre?
És még folytathatnánk.
Nem újdonság, hogy az ezekre a kérdésekre érkező válaszok igazságtartalma hatalmas jelentőséggel bír.
Az attribúciós/hozzárendelési modellezés ezeket a kérdéseket hivatott a valósághoz hűen megválaszolni (amennyire lehetséges).
Miről lesz szó a cikkben?
- Mik az attribúciós modellek?
- Miért fontos beszélni róluk?
- Standard Google Analytics modell(ek)
- Pozíció alapú modell (Position based)
- Időkésleltetés modell (Time decay)
- Adatközpontú modell (Data driven)
- Modellek összehasonlítása
- Konklúzió
Mik az attribúciós modellek?
“A hozzárendelési modell olyan szabály vagy szabályok együttese, amely meghatározza, hogy az eladások és a konverziók utáni jóváírások milyen kapcsolattartási ponthoz legyenek hozzárendelve a konverziós útvonalakon.”

Forrás: windsor.ai
A fancy Google-ös definíció után evezzünk egy kicsit hétköznapibb vizekre.

Egy átlagos péntek estén egy alkoholfogyasztásra alkalmas installációban találjuk magunkat, ahol mindenki saját ízlése szerint elfogyaszt adott mennyiségű alkoholt, adott mennyiségű ital fajtából, amely sokunk esetében ittas állapothoz vezet.
Másnap a gőzölgő húsleves illatára ébredünk frissen és üdén (mint mindig), és szeretnénk kiértékelni a tegnap estét alkoholfogyasztás szempontjából. Miért ne tennénk?
Itt merülnek fel a kérdések az ittassággal kapcsolatban:
# Állíthatjuk-e azt, hogy az első ital felel érte 100%-ban? (Első kattintás)
# Mondhatjuk-e azt, hogy az utolsó ital felel érte 100%-ban? (Utolsó kattintás)
# Talán mindegyik ugyanakkora mértékben? (Lineáris)
Mindegyik fenti kérdés egy hozzárendelési modell elve szerint értékeli az estét.
Érezhetően helytelenül.
Csakúgy, mint egy éjszakai tivornyázást, a vállalatunk online marketing csatornáit sem értékelhetjük egylépcsős rendszerben (vagy lineáris értékeléssel), sokkal inkább érdemes egy folyamatként kezelve, melynek különböző súlyú interakciós pontjai vannak.
A továbbiakban ezek és az ehhez hasonló hozzárendelési szabályok működési elveit és létjogosultságukat veszem górcső alá.
Miért fontos beszélni róluk?
Remélem nem kell senkit túlságosan győzködni, hogy mennyire fontos a bevezetésben elhangzott kérdésekre a valósághoz leginkább közelítő választ megtalálni, de azért pár érv amellett, hogy miért is érdemes igazán foglalkozni ezzel a témával:
- Valós(abb) képet kapunk a teljesítményről
- Optimalizálási folyamataink fejlőd(het)nek
- Jobban megért(het)jük a vásárlási folyamatokat, ügyfeleinket
Fontos megjegyezni, hogy az attribúciós modellezés jelenleg nem egy egzakt tudomány. Egyelőre nincs olyan “best practice”, amire bátran azt lehetne mondani, hogy tökéletes megoldás, így kénytelenek vagyunk a szuboptimalitás svédasztaláról válogatni.
Megjegyzés: a fenti felsorolásban zárójelekkel emeltem ki, hogy továbbra is igaz, hogy az olyan adat, amivel nem kezdünk semmit, önmagában teljesen értéktelen. Igyekezzünk a reális(abb) kép megalkotása után azt felhasználva döntéseket hozni.
A továbbiakban a – szerintem – releváns hozzárendelési modellekről lesz szó, de előtte pár szóban bemutatom a kihagyott modellek sajátosságait.
Röviden összefoglalva: az első kattintás modellnél értelemszerűen a legelső interakciós pont kapja az érték 100%-át, míg a lineárisnál mindegyik pont ugyanannyi értéket kap. Első kattintás megfontolását brandépítő kampány vagy nagyon kevés termék (darabszámra) esetében érdemes megfontolni. Lineáris modell mellett csupán annyi szól, hogy minden lépés kap értéket, a súlyozás viszont végzetes gyengesége.
Standard Google Analytics modell(ek)
Google Analytics riportokban az alapértelmezett az utolsó, nem közvetlen kattintás (last non-direct click) modell, mely a direkt forrást közvetlenül megelőző csatornához társítja az érték 100%-át (ha volt ilyen csatorna az utóbbi 6 hónapban).
Ezzel a Google jócskán a saját malmára hajtja a vizet, hiszen mind a fizetett, mind az organikus csatornák ezzel jócskán felértékelődnek a direkttel szemben.
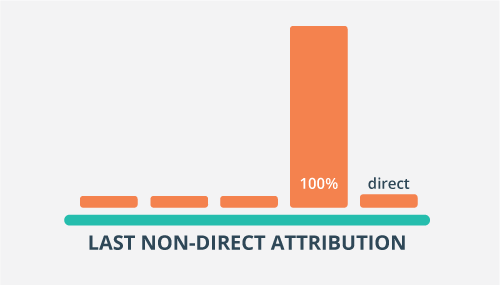
Forrás: blog.raak.be
Jogosan merül fel a kérdés, hogy mennyi értékbeli jelentősége van annak, hogy a felhasználó emlékezett a weboldalunkra vagy esetleg lementette az URL-t és direktben érkezett vissza vásárolni (kiegészítés: sok esetben a direct / (none) azt jelenti, hogy a Google nem tudja, hogy honnan érkezett a vásárló).
Nehéz kérdés. A zérus értéknél mindenesetre többet érdemel.
Fontos még megemlíteni, hogy az utolsó, nem közvetlen kattintás csak a NEM többútvonalas csatornákról (Multi-Channel Funnels) szóló jelentések esetében alapértelmezett (például a forrás/médium riport).
Ha az MCF jelentésekben járunk (segített konverziók, legjobb konverziós útvonalak, időeltolódás, útvonal hossza riportok) akkor úgy nézzük, hogy azok sima utolsó kattintás (last click) modell szerint vannak értékelve, vagyis a konverziós érték 100%-át az utolsó csatorna kapja (akkor is, ha az a direkt volt), viszont csak az utóbbi 90 napot veszik figyelembe.

Forrás: blog.raak.be
Mindkét esetben érdemes erős fenntartásokkal kezelni a számokat, hiszen ma már egy “one-touch” (egy interakciós pontot értékelő) modell jócskán elavultnak számít.
Na de akkor mi, ha nem ezek?
Pozíció alapú modell (Position based)
Kezdjük a “multi-touch” (több interakciós pontot értékelő) modellek listáját a pozíció alapú (position based) modellel.
E modell esetében az első és utolsó csatorna kap 40-40%-ot, míg a maradék 20% a köztes csatornák között osztódik szét arányosan (függetlenül attól, hogy hány volt).
Itt már annyival közelebb járunk az igazsághoz, hogy az összes csatornát figyelembe vesszük az értékeléskor, viszont a 40-20-40 elosztás nem feltétlenül ideális megoldás minden termék, kategória vagy piac számára.
Ha szeretnénk az első és az utolsó interakciót kiemelten díjazni, vagyis amikor először találkozott velünk a fogyasztó, és amikor eldöntötte, hogy rendel, akkor ez már egy jó váltás lehet az utolsó kattintás modellről, ha úgy érezzük, hogy a vállalatunk tud azonosulni ezzel az értékrenddel.

Forrás: blog.raak.be
Megjegyzés: ha az elv tetszik, de nem 40-20-40 elosztást preferálunk, akkor egy testreszabott hozzárendelési modellként kedvünk szerint létrehozhatunk egy más arányt alkalmazó verziót (akár további finomításokkal).
Időkésleltetés modell (Time decay)
Következzen a listán az időkésleltetés (time decay) modell.
Egy egyszerű elv szerint számol, miszerint a konverzióhoz legközelebb álló interakciós pontok kapják a legtöbb értéket, vagyis az idő függvényében változik az érték eloszlása. Ezt exponenciális késleltetésnek hívják.
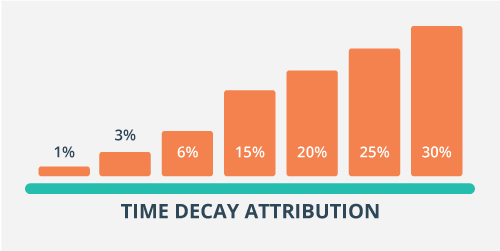
Forrás: blog.raak.be
Társul még a modellhez egy úgynevezett “felezési idő” beállítás is. Itt azt mondhatjuk meg a rendszernek, hogy a konverzió napjához képest hány napnak kell eltelnie, hogy a soron következő kapcsolattartási pont az utána következő pont értékének felét kapja meg (7 nap az alapértelmezett, módosítható).
Egyszerűsítve: a konverziót 7 nappal megelőző interakció fele annyi értéket fog kapni, mint a konverzió napján történt kattintás.
Számos szakértő szerint az alapértelmezett modellek között ez a legjobb, mert kiállja a józan ész próbáját: minél régebben találkozott a fogyasztó az adott csatornával, annál kevésbé játszik szerepet a konverzióban. Elvégre, ha olyan jó volt, akkor miért nem konvertált ott?
Ezzel könnyen egyet lehet érteni, hiszen a logika valóban helytálló, viszont számos esetben nem követendő példa, mert az első interakció túlságosan alulértékelődik.
Például: branding kampány esetében (ahol kiemelten fontos az első interakció), vagy ha (nagyon) drága termékeket értékesítünk, szintén kétségbe vonható ennek az értékelési logikának a használata (lásd: pozíció alapú modell).
Az viszont kétségtelen, hogy általában nem nagyon tudunk az időkésleltetés modellel melléfogni, így kezdésnek a legtöbbször ennek az alkalmazása ajánlott, főleg ha eddig csak utolsó kattintás modellt használtunk.
Megjegyzés: eddig nem esett róla szó, de a multi-touch modellek használatakor Google Ads-ben törtkonverziókkal is fogunk találkozni (ha Adsben is szeretnénk alkalmazni más modellt, ami az optimalizálás szempontjából kifejezetten ajánlott). Ne lepődjünk meg, ha egy kulcsszavunk 0.5 konverziót hozott, valamint emiatt a konverziós költség oszlopot is fenntartásokkal kezeljük (főleg szkriptek vagy automatizált szabályok esetén figyeljünk ezekre). Ha például 0.5 konverziót hozott egy szó 2000 Ft-os költés mellett, akkor a konverziós költség 4000 Ft lesz, ami igen messze esik a valóságtól.
Adatközpontú modell (Data driven)
Végül, de nem utolsó sorban beszéljünk kicsit a “nagyágyúról”. Jelenleg csak Google Analytics 360-at használóknak van hozzáférése az adatközpontú hozzárendelési modellhez, ami a fiók múltbeli adatai alapján rendeli hozzá az egyes interakciós pontokhoz a konverzió értékét.
Ez a funkció akkor érhető el, ha a megelőző 28 napban minimum 400 konverzió (egy adott cél vagy tranzakció esetén, nem összesen, és legalább 2 interakciós ponttal) történt ÉS minimum 10 000 útvonal generálódott az adott Google Analytics nézetben, továbbá az összekapcsolt Google Ads fiókban a keresési hálózaton legalább 15 000 kattintás és 600 konverzió keletkezett az utóbbi 30 napban.
A modell hetente frissül, legfeljebb 4 interakciót vesz figyelembe, maximum 90 napos távot vizsgál az egyes konverzió előtt, továbbá nem veszi figyelembe a direkt csatornát, ha volt marketingtevékenység (vagyis másik csatornán keresztül is kapcsolatba lépett velünk a látogató) a direktet megelőző 24 órán belül.
Érezhető tehát, hogy az adatközpontú modellnek is megvannak a korlátai.
A kalkulációnak 2 fő része van:
Első lépés: az adatközpontú modell nem csak a konvertáló adatokat használja fel, hanem azokat is, amik nem vezettek vásárláshoz, vagyis MINDEN adatot figyelembe véve vizsgálja azt, hogy az egyes érintkezési pontok jelenléte milyen hatással van a konverziós valószínűségre.
Második lépés: a kapott valószínűségi adatkészletre egy olyan algoritmust alkalmaz, mely a kooperatív játékelmélet Shapley-érték nevű fogalmára épül.
Jól hangzik, igaz?
Tegyük meg a bizalmi lépést a Google felé, hogy elhisszük, hogy ez jobb, mint a többi, és ha van rá módunk legalább egy tesztelés/összehasonlítás erejéig használjuk.
Modellek összehasonlítása
Eddig nem esett szó az egyik talán legfontosabb eszközről ebben a témában, ami nem más, mint a modell-összehasonlító eszköz, melyet Google Analytics > Konverziók > Hozzárendelés > Modell-összehasonlító eszköz fülön találunk.
Miben rejlik az ereje?
Bármilyen adatvesztés vagy módosítás nélkül megvizsgálhatjuk, hogy hogyan változnának az egyes csatornák konverziós számai, ha másik hozzárendelési modell szerint értékelnénk őket.
A tranzakciók száma, költsége és értéke alapján is megvizsgálhatjuk a különbségeket.
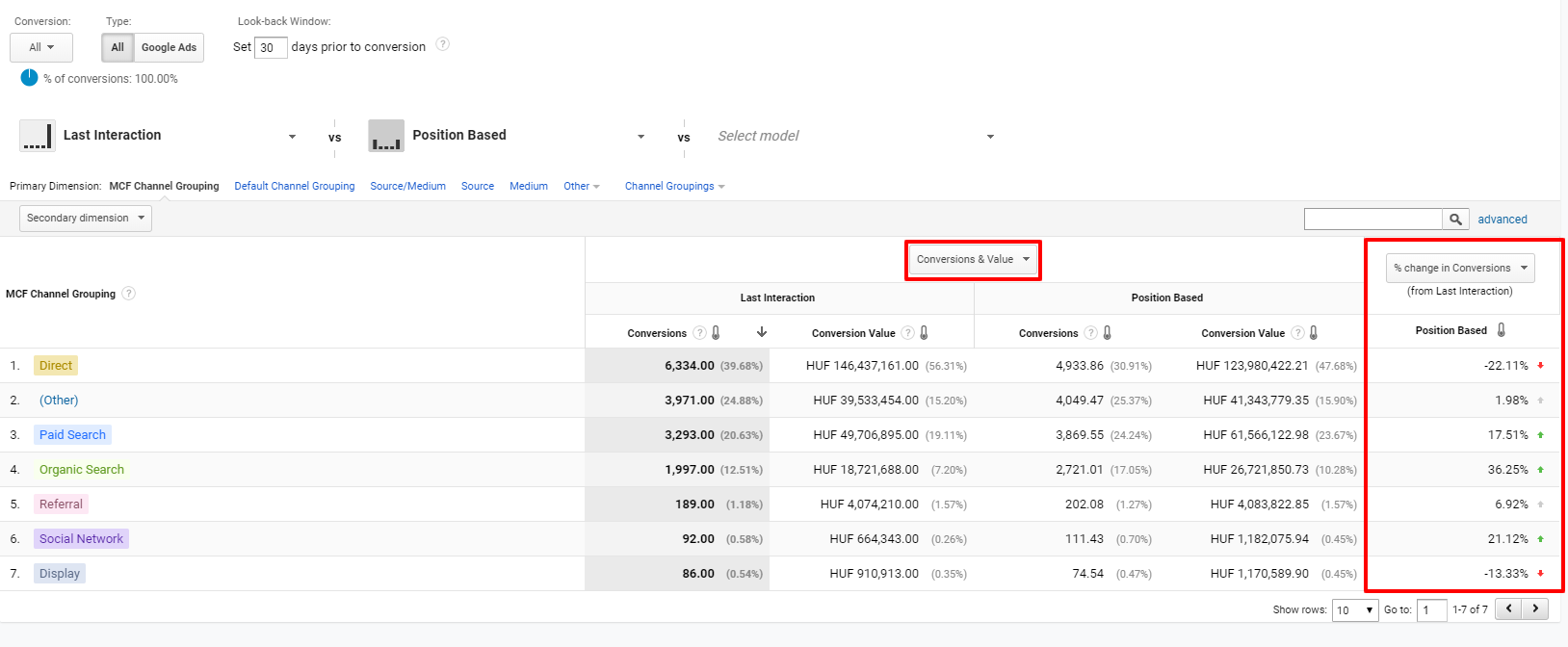
A fenti képen az utolsó kattintás modellt hasonlítom össze a pozíció alapúval konverziós darabszám és érték alapján. A pirossal bekeretezett oszlop a konverzió darabszámában bekövetkezett százalékos változást mutatja csatornák szerint (ugyanezt az érték alapján is nézhetném). Ezt az oszlopot érdemes nagyon figyelmesen megvizsgálnunk, akár több modellt is összehasonlítva (max. 3-at lehet), mert nagyon érdekes számokkal találkozhatunk.
Amikre gondolhatunk a számok vizslatásakor:
# Lehet, hogy mégis jól teljesít a Display kampányom, csak nem tudtam róla?
# Lehet, hogy mégsem kellett volna kirúgnom a SEO ügynökségemet?
# Lehet, hogy több pénzt kellene Google Ads-re költenem?
A kép csak példa, nem ebből olvastam ki a felmerülő kérdéseket, noha a Displayen kívül egészen valósághű.
Óvakodjunk itt is az egydimenziós gondolkodástól. Ha látjuk, hogy más hozzárendelési modell mellett jócskán csökken például az e-mail csatorna értéke, az még nem jelenti azt, hogy nem fontos a vásárlási folyamat során, és a belefektetett energia/pénz csökkentése az összbevételben is megmutatkozhat.
Konklúzió, TL;DR
Ahogy a bevezetésben is említettem, az attribúciós modellezés egy nagyon nehéz téma, és nem kevés gondolkodást igényel. Itt nem a modellek értékelési elvére gondolok, hanem a megfelelő kiválasztására az adott szituációban.
Remélem egyetértesz azzal, hogy a nehézsége ellenére egy igenis fontos téma, és ha már egy-két dolgon elgondolkozol emiatt, akkor már megérte megírni ezt a cikket.
Jöjjön akkor a TL;DR rész visszaolvasáshoz vagy az elfoglalt embereknek:
- Legfontosabb: használjuk aktívan a modell-összehasonlító eszközt! Ingyenes, egyszerű, gyors. Mi kell még?
- Az első és utolsó kattintás modell soha nem a legjobb. Vannak esetek, amikor nem annyira kártékonyak, de igyekezzünk multi-touch modelleket használni (inkább ne a lineárisat).
- Gondolkozzunk folyamatokban, ne ragadjunk le az egylépcsős rendszernél!
- Ha van rá lehetőség használjunk adatközpontú modellezést (legalább egy összehasonlítás erejéig)
- Kezeljük fenntartásokkal a Google Analytics és Ads adatokat, próbáljunk meg a miértek mögé látni
- Semmit sem érnek az adatok, ha nem használjuk fel őket a döntéshozatalkor
Köszönöm az olvasást!
További kiváló olvasmányok a témában (angol nyelven):
https://www.kaushik.net/avinash/multi-channel-attribution-modeling-good-bad-ugly-models/
https://www.lunametrics.com/blog/2017/12/04/google-analytics-attribution-models/
https://www.lunametrics.com/blog/2017/12/04/marketing-attribution-in-google-analytics/
https://savvyrevenue.com/blog/ecommerce-attribution-models/
https://www.optimizesmart.com/advanced-attribution-modelling-google-analytics/
https://klientboost.com/analytics/ecommerce-attribution/
https://www.optimizesmart.com/attribution-modelling-reports-in-google-ads-google-adwords/
https://www.optimizesmart.com/attribution-modeling-case-study-introducing-effective-click-optimization/



{kind=link}
{kind=link}
{kind=link}